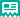
M1系列在长上下文理解任务中 (MRCR)表现较优?金十数据6月17日,寂寞已久的六小龙之一MiniMax酝酿了一个流行为,发外将衔接五天颁布厉重更新。此日第一弹是开源首个推理模子MiniMax-M1。
依据官方的陈诉,MiniMax-M1众项基准测试比肩DeepSeek-R1、Qwen3等开源模子,靠拢海外的最领先模子。
官方博客还提到,基于两大技艺立异,MiniMax-M1熬炼经过高效得“越过预期”,只用了3周时刻、512块H800 GPU就落成加强练习熬炼阶段,算力租赁本钱仅53.47万美元。这比一着手的预期少了一个数目级。
众位开采者一经第有时间张开测评。前illasoft技艺总监@karminski正在社交平台颁布了己方对MiniMax-M1的测评,认同其是“开源MoE第一梯队”。
@karminski着重测试了MiniMax-M1-80K的写代码才力,用“拆烟囱”这一编程案例实测发觉,MiniMax-M1-80K正在提示词下一次过,他提到DeepSeek-R1-0528 以至 Gemini-2.5-Pro 都没能一次通过,这不妨得益于其“熬炼原料足够新”和“考虑时众次反刍告成避坑”的才力。
舛误是,从天生的前端页面来看, 样式不是很颜面,因而用来天生高度创意的实质不妨见面对不敷发散的题目, 但反过来编程的指令根据和无误性会更好。其它光影成绩不是很好,也是熬炼亏折的地方。
也有网友提到,测试发觉MiniMax-M1模子中文写作是厉谨优先的,幻觉较低,以根据文本和指令为第一。这正在着重发散的邦内模子中较量可贵。
依托这一基本,M1系列正在长上下文判辨使命中 (MRCR)外示较优,从测试目标看,超越了一切开源权重模子,以至超越海外的顶尖模子OpenAI o3和Claude 4 Opus,环球排名第二,仅轻微差异掉队于Gemini 2.5 Pro。
“无穷长的长文本才力是MiniMax团队无间正在打磨的厉重维度,关于做社交操纵、心情随同操纵,Agent等来说是很闭节的技艺。”云启资金协同人陈昱正在6月的大会论坛上示意。云启是MiniMax的天使轮投资机构。
正在代码才力(SWE-bench)上,MiniMax-M1明显超越大局部隔源模子,仅轻微差异次于DeepSeek最新颁布的R1。
MiniMax示意,MiniMax-M1的长文本才力得益于闪电防卫力机制为主的夹杂架构,这一架构使得M1正在实行长文本的上下文输入和深度推理时均有算力功用上风。MiniMax举例称,正在用8万Token深度推理的时分,只必要行使DeepSeek R1约30%的算力。
除此以外,MiniMax提出的另一立异是加强练习算法CISPO。官方博客示意,正在数学AIME的测验中,这比字节近期提出的 DAPO 等加强练习算法收敛功能疾了一倍,明显优于 DeepSeek早期行使的 GRPO。这也是最终算力本钱不到54万美元的原故。
由于相对高效的熬炼和推理算力行使,MiniMax的订价性价较量高,官方直接对标性价比之王DeepSeek喊话,“两种形式都比 DeepSeek-R1 性价比更高,另一种形式DeepSeek模子不扶助。”
险些与MiniMax同时,六小龙之中的其它一家月之暗面也正在今日开源了编程模子 Kimi-Dev-72B。依据官方颁布的新闻,这一模子是基于阿里云的Qwen2.5-72B 微调获得的。依据陈诉,这一模子正在SWE-bench编程基准测试中博得了环球最高开源模子水准,结果超出了新版DeepSeek-R1。
这激励了对其高分是否源于“过拟合”的质疑,这是呆板练习中的常睹题目,指模子正在熬炼集上外示优异,但正在未睹过的新数据上预测才力明显降落。目前月之暗面尚未颁布精细技艺陈诉。
DeepSeek正在岁首搅动风暴后,AI六小龙有的映现高管出走风浪,有的寂寞已久,用心熬炼半年,看起来这些厂商一经做好了新的预备,接连参预这场大模子之争中。
MiniMax预告,后续四天将有更众更新。此前“海螺02(0616)”视频模子已现身AI视频竞技场,并博得第二名的佳绩,业界一般预期海螺新版本即将正式亮相。假如海螺能延续M1正在本钱或才力上的打破,或将进一步搅动众模态AI的式样。
转载请注明出处。

 相关文章
相关文章




 精彩导读
精彩导读





 热门资讯
热门资讯 关注我们
关注我们
